Rows: 1000 Columns: 14
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): Sex, STRESS_EXIST
dbl (12): Age, Height, Weight, BMI, DM, HTN, Smoking, MACCE, Death, MACCE_da...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
데이터를 읽으면 각 변수들을 어떤 형태(숫자형, 문자형)로 읽었는지 표현되는데, 바꾸고 싶은 것이 있으면 아래와 같이 col_types 옵션을 이용하면 된다.
## Character: col_character() or "c"a<-read_csv("https://raw.githubusercontent.com/jinseob2kim/R-skku-biohrs/master/data/smc_example1.csv",col_types =cols(HTN ="c"))
이제 데이터를 살펴보면 HTN 변수가 문자형이 된것을 볼 수 있다.
a
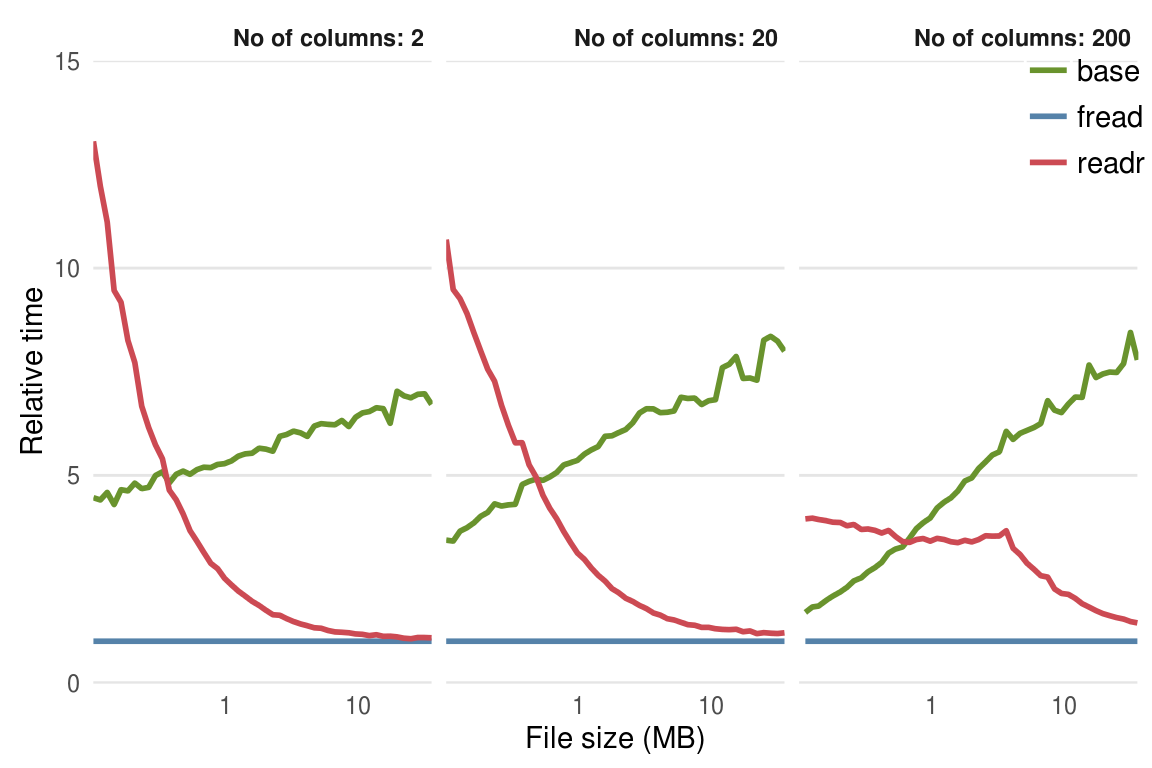
기본 함수인 read.csv 와 비교했을 때 아주 작은 데이터에서는 장점이 없으나, 그 크기가 커질수록 read_csv가 더 좋은 성능을 보임이 알려져 있다(Figure @ref(fig:readfunc)).
기존의 data.frame 외에도 tbl_df, tbl 와 같은 것들이 추가되어 있다. tibble은 data.frame보다 좀 더 날 것(?)의 정보를 보여주는데, 범주형 변수를 factor가 아닌 character 그대로 저장하고 변수명을 그대로 유지하는 것(data.frame에서 변수명의 특수문자나 공백은 .으로 바뀜)이 가장 큰 특징이다. tibble의 추가 내용은 jumpingrivers 블로그4를 참고하기 바란다.
tidyverse 생태계에서 가장 중요한 것을 하나만 고르라면 magrittr 패키지의 %>% 연산자를 선택하겠다. %>%은 Rstudio에서 단축키 Ctrl + Shift + M (OS X: Cmd + Shift + M)로 입력할 수 있는데, 이것을 이용하면 의식의 흐름대로 코딩을 할 수 있어 직관적인 코드를 작성할 수 있다. head함수를 통해 %>%의 장점을 알아보자.
head(a)와 a %>% head는 같은 명령어 “a의 head를 보여줘”로, a %>% head가 생각의 흐름이 반영된 코드임을 알 수 있다. 일반적으로 %>% 연산자는 함수의 맨 처음 인자를 앞으로 빼오는 역할을 하고 f(x, y)는 x %>% f(y)로 바꿀 수 있다. 맨 처음 인자가 아닐 때에는 y %>% f(x, .)과 같이 앞으로 빼온 변수의 자리에 .를 넣으면 된다. 예를 들면 아래에 나오는 세 명령어는 모두 같다.
%>%의 진가는 여러 함수를 한 번에 사용할 때 나타나는데, head와 subset을 동시에 쓰는 경우를 예로 살펴보겠다.
## head(subset(a, Sex == "M"))a%>%subset(Sex=="M")%>%head
이 명령어는 a에서 남자만 뽑아서 head를 보여줘로 기존의 head(subset(a, Sex == "M"))보다 훨씬 직관적이며 함수가 3개, 4개로 늘어날수록 비교가 안될 정도의 가독성을 보여준다. 남자만 뽑아 회귀분석을 수행하고 그 계수와 p-value를 구하는 예를 살펴보자. 먼저 기존의 코딩 스타일대로 명령을 수행하면 아래와 같다.
b<-subset(a, Sex=="M")model<-glm(DM~Age+Weight+BMI, data =b, family =binomial)summ.model<-summary(model)summ.model$coefficients
다음은 %>% 를 이용한 코딩이다.
a%>%subset(Sex=="M")%>%glm(DM~Age+Weight+BMI, data =., family =binomial)%>%summary%>%.$coefficients
%>% 연산자로 쓴 코드는 읽기 쉬운 것은 물론 불필요한 중간변수(b, model, summ.model)가 없어 깔끔하고 메모리의 낭비도 없다. 딱 하나 주의할 점은 코드를 내려쓸 때 각 줄은 반드시 %>%로 끝나야 한다는 점이다. 예를 들어 아래의 코드를 실행하면 맨 윗줄만 실행되는 것을 확인할 수 있다.
변수명 대신에 열 번호를 넣어도 되며 Sex:Height을 이용해서 Sex와 Height 사이의 모든 변수를 선택할 수도 있다. arrange 함수와는 달리 "Sex"와 같은 문자열도 그대로 입력 가능하며, 아래의 방법들은 모두 a %>% select(Sex, Age, Height)와 같은 코드이다.
[[1]]
Call:
lm(formula = Death ~ Age, data = x, family = binomial)
Coefficients:
(Intercept) Age
0.0461858 0.0001931
[[2]]
Call:
lm(formula = Death ~ Age, data = x, family = binomial)
Coefficients:
(Intercept) Age
-0.208833 0.004355
위 예시에서 알 수 있듯이 lapply에서 복잡한 함수를 반복하려면 function(x) 문이 꼭 필요하고 가독성을 저해하는 원인이 된다. 그러나 map에서는 ~로 간단히 function(x)를 대체할 수 있다. 아래 코드를 살펴보자.
[[1]]
Call:
lm(formula = Death ~ Age, data = ., family = binomial)
Coefficients:
(Intercept) Age
0.0461858 0.0001931
[[2]]
Call:
lm(formula = Death ~ Age, data = ., family = binomial)
Coefficients:
(Intercept) Age
-0.208833 0.004355
map함수를 이용하여 function(x)를 ~로, 성별 데이터에 해당하는 x를 .으로 바꾸니 훨씬 읽기가 쉬워졌다.
이번엔 같은 회귀분석을 수행한 후 Age의 p-value만 뽑는다고 하자.
a%>%group_split(Sex)%>%sapply(function(x){lm(Death~Age, data =x, family =binomial)%>%summary%>%.$coefficients%>%.[8]## p-value: 8th value})
[1] 9.016998e-01 2.094342e-07
%>% 연산자를 이용해 나름대로 읽기 쉬운 코드가 되었다. 이것을 map_dbl로 다시 표현하면 아래와 같다.
기존 코드는 .$coefficient와 .[8] 같은 부분이 거슬렸는데, map("coefficients"), map_dbl(8)으로 바꾸니 보기에 훨씬 깔끔하다. 참고로 map("coefficients") 은 map(`[[`, "coefficients")의, map_dbl(8)은 map_dbl(`[`, 8)의 축약형 표현이다. 사실 아까 다루었던 첫 번째 값 뽑기의 경우도 아래와 같이 더 간단하게 쓸 수 있다.
map을 통해 함수의 모든 중간과정을 따로따로 구현한 것도 장점이다. 에러가 발생했을 때 드래그로 중간과정까지만 실행할 수 있어 함수의 어느 부분에서 에러가 발생했는지를 쉽게 알아낼 수 있다.
map2, pmap: 입력 변수 2개 이상
2개 이상의 입력값에 대해 반복문을 수행하는 함수로는 mapply가 있다. 이것의 tidyverse 버전이 map2와 pmap인데 전자는 2개의 조건에, 후자는 리스트 형태로 입력값의 갯수에 상관없이 반복문을 구현할 수 있다. 본 강의에서는 간단한 예만 다루어 보겠다. 먼저 mapply를 이용해서 여러 입력값의 합을 구하는 코드를 살펴보자.
[1] "Alice was born at LA" "Bob was died at New york"
마치며
지금까지 tidyverse 생태계에서 몇 가지 패키지를 이용해 데이터를 다루는 방법을 살펴보았다. 앞서 말했듯이 이 생태계에서 가장 중요한 것은 %>% 연산자를 이용하여 의식의 흐름대로 코딩을 수행하는 것이며, 이후 나머지 내용을 하나씩 적용해나가면 어느 순간 tidyverse 없이 살 수 없는(?) 자신을 발견하게 될 것이다. 본 글에서 다루지 않은 내용인 long, short 포맷을 다루는 tidyr, 문자열을 다루는 stringr, factor를 다루는 forcats, 날짜를 다루는 lubridate 그리고 모델을 다루는 modelr과 broom 등은 R for Data Science[^8]와 Rstudio cheetsheet[^9]를 참고하기 바란다. 다음번에는 빠른 속도가 장점인 data.table를 다시 한번 정리해 볼 생각이다.